Fighting for quality news media in the digital age.
Meanwhile Google news partnerships boss says “overly summarising” news content runs counter to its mission.
By Charlotte Tobitt
Google’s new AI-generated search results will lead to a traffic drop but it won’t be a “dramatic downward dive” for news-focused publishers, SEO expert Barry Adams has predicted.
Adams reassured publishing leaders at the WAN-IFRA World News Media Congress in Copenhagen on Wednesday that if they primarily produce news content, he believes they are “going to be okay”.
Adams was speaking a day after Google‘s vice president for global news partnerships Jaffer Zaidi told the conference it would run “counter” to the tech platform’s mission of ensuring access to information if it was in the business of “overly summarising” news content.
Google AI Overviews began rolling out in the US this month and follow last year’s Search Generative Experience trial.
Related
For certain types of query, users are shown an AI-generated written response at the top of the search results before the usual list of links follow underneath.
Thanks for subscribing.
Most have at least one cited source link, according to Polemic Digital founder and SEO consultant Adams, with six links on average. Most cited links are pages ranked on the first page of the search results already.
However Adams said that in his testing of several hundred queries he has never seen an AI Overviews response in a search result that generates a Top Stories box – the section at the top that is most coveted by news publishers.
His theory is that AI Overviews is “mutually exclusive” from the Query Deserves Freshness ranking function – meaning search results where Google deems the user wants up-to-date, new information, often triggering the Top Stories box.
He believes therefore that publishers that do purely news are “probably okay, for now – who knows?” but warned evergreen content will be more significantly affected.
So far there is mainly only anecdotal evidence about the impact of the introduction of AI Overviews in the US on traffic, especially as it is difficult to track. Users must be logged in to their Google account and using the Chrome browser in order to see an AI Overviews result.
But Adams said it appears that about 14% of queries on average now show AI Overviews by default. An additional 28% of queries give users the option to generate an AI summary while 58% have no AI Overviews features.
Searches using words like “how” and “why” are most likely to trigger an AI-generated result while commercial-related queries using the word “buy” are the least likely.
How will it impact on traffic? Adams said: “The short answer is we probably don’t really know yet.”
But early anecdotal data shows that if AI Overviews are on a page and your page is not cited as a source, you lose about 2.8% of traffic.
“If you are a cited source in the AI Overview, you lose more traffic, you don’t actually gain any more traffic, because people will just read the AI Overview and say ‘oh yeah’,” Adams added. “They don’t feel the need to click through to your search result.” That traffic loss is 8.9%.
Google chief executive Sundar Pichai told The Verge the opposite last week, claiming that “people do jump off on it. And when you give context around it, they actually jump off it. It actually helps them understand, and so they engage with content underneath, too.
“In fact, if you put content and links within AI Overviews, they get higher clickthrough rates than if you put it outside of AI Overviews.”
Adams told publishers the actual traffic impact of AI Overviews appears to be “a net negative so far, but not disastrous”.
“AI Overviews will not destroy your search traffic. You will feel impact, but it’s not going to be a dramatic downward dive…
“If you produce news content primarily, you’re probably going to be okay. I don’t see that news is going to suffer too much. Because those Top Stories boxes will still be the main driver of the traffic and I do not see them in conjunction with AI Overviews.”
[Read more: Why AI-powered search from Google may NOT be disaster for publishers]
Adams added that Google does not feel it has an obligation to send traffic to publishers and is increasingly becoming a walled garden.
The rollout of AI Overviews, he said, is “not the death of search – just another brick in the wall”.
He added: “There’s a lot of panic at the moment. I don’t think this is worth panicking about. I do think it’s an interesting point of conversation… I think AI Overviews are primarily designed for Google to show the world they’re in the AI race, that OpenAI is not going to overtake them… but ultimately it’s just not a very good feature.”
Adams noted there are “definitely massive inaccuracies” in the AI Overviews results so far, citing for example a response telling users they could use “non-toxic glue” to make cheese stick to pizza better. These issues have in part been put down to the fact Google signed a deal to use Reddit content to train its AI tools.
Google has said results such as these were “generally very uncommon queries, and aren’t representative of most people’s experiences”.
In addition, Adams pointed out, sometimes Google cites sources that are not actually sources, showing for example a link to healthyfitnessblogs.com which no longer exists.
Meanwhile users “hate it”, he said, pointing to a “huge spike” in Google Trends asking for help turning off AI results.
“But you’re probably not going to get rid of this anytime soon because it’s a monetisation opportunity. There will be ads coming into these AI Overviews very, very soon and Google is really all about maximising shareholder value, and increasing their revenue, so yeah, we’re going to be stuck with this for the foreseeable future.”
Adams also said, however: “It will get better, obviously. Google will iron out the kinks, will sort out the issues, but I do suspect there will always be problems with it because that’s the nature of a large language model.
“A large language model is not a knowledge base – it’s not Wikipedia. It’s a word predictor on steroids. They will hallucinate answers. They will get answers from inaccurate sources. And therefore you always need to be double checking what you’re reading in those boxes.”
Adams’s analysis came after Google’s news partnerships boss Jaffer Zaidi promised publishers: “There’s no path forward for us that doesn’t acknowledge the importance of news and the high-quality output of this industry in some way, shape or form and we’ll always put the publisher ecosystem at the forefront of our response.”
Zaidi acknowledged there are “many concerns and questions around summarisation displays” but said Google’s operating principles “institutionalise the importance of high-quality content sources and our role in connecting users to publishers”.
Zaidi said Google has “seen in any space in which we’ve operated the limits to even things like summarisation.
“I think the expectation that our users have of us at the end of the day is that we actually provide a window into the world so that they can interact through us sometimes, and then we make connections for them into the ecosystem.
“If you think about what it means to interact with Google we’re really an access point for you to get to what you’re looking for and I think we’re very mindful of the trust that we’ve built with our users… if we overextend in any way, shape or form I think that comes to some real consequences.”
He said “being a publisher ourselves, or being in the business of overly summarising, runs counter” to this mission.
Zaidi did not answer any questions directly about AI Overviews but said he views Google’s relationship with publishers as a “partnership” and that “I want us to have some shared ambition for how we actually use this technology and capability to do interesting and hopefully amazing things”.
Email pged@pressgazette.co.uk to point out mistakes, provide story tips or send in a letter for publication on our “Letters Page” blog
Thanks for subscribing.
Uncategorized
'Jeong Dae-se ♥'Myeong Seo-hyun"The flight attendant on the presiden – SportsChosun
By Sohee, Kim
Oct 27, 2024
|

Myung Seo-hyun, the wife of former soccer player Jung Dae-se, confessed her sorrow due to the career break.
In MBN ‘Determined to divorce at least once’ (hereinafter ‘Hanigyeol’) aired on the 27th, Myung Seo-hyun, who had a quarrel with her husband due to a conflict with her husband, met her former colleague at work and lived as a ‘Gyeongdan woman’ and confessed her hard feelings.
On this day, Myung Seo-hyun gave a special lecture for aspiring flight attendants. At the appearance of Myung Seo-hyun, who is neatly decorated, Jeong Dae-se said, “‘Isn’t he going to meet a man?'”, but he has never seen him teach. I can’t help but twinkle when I see you at workHe said, “I was impressed by Myung Seo-hyun’s concentration on work.
|

After the lecture, Myung Seo-eun met a close friend, a former crewmate. Myung Seo-hyun, who has not been out without children in a long time, shook his head firmly when his friend said “Do you have a hobby?”
Myung Seo-hyun said “When I’m at home, all I have to do is watch my child or cook for my husband ” and “It seems that I don’t exist to live only as someone’s wife and mother. I don’t feel like I’m living.”
The friend asked “Didn’t you get married and quit the company because of your child?” and Myung Seo-hyun confessed honestly, “I quit because of my husband, not because of my child.”
When asked if he still misses his work, Myung Seo-hyun said “Yes. I have a lot of regrets left”Didn’t I get on the presidential plane?” I got a honey moon baby right after I got married. I became pregnant right away. I don’t know what was so urgent..”At the same time as he got married, he expressed his sorrow for a career break.
|

Jeong Dae-se, who was watching this, said “I had patriarchal thoughts at the time. Working reduces the love you give your child. So (to Myung Seohyun) ‘I want you to take care of them’ had said. So I quit, and (my wife) must have given up on the big one.”
He then flew ” (wife) on the presidential plane. There will be tens of thousands of Korean crew members, and if they make the top 13, they will be on the presidential plane. But he gave up and married me”When I see it again, I’m sorry, and I think it’s a big fact that I gave up.”
|

Later, Myung Seo-hyun was asked by his friend “Don’t you want to work again?”, and the employment of experienced workers appeared when he was 32 years old”. I wanted to do it. But if you are the youngest at 32, your pride will be hurt. Anyway, I can’t imagine my husband not being home when he is playing,” he said, revealing that he had no choice but to focus on his inner workings as a soccer player’s wife.
However, Myung Seo-hyun doesn’t regret it. Myung Seo-hyun was impressed by saying, `Rather than regretting it, I have a child, so I live with it.’
yaqqol@sportschosun.com
© 2000-2024 Copyright sportschosun.com All rights reserved.
How Compression Can Be Used To Detect Low Quality Pages – Search Engine Journal
Join us as we share insights from the top SEOs at the world’s largest traffic-driving websites. Instead of guesswork, you’ll discover how to leverage real data to align your team and fast-track growth with five proven and actionable tactics you can implement immediately.
Discover the latest trends, tips, and strategies in SEO and PPC marketing. Our curated articles offer in-depth analysis, practical advice, and actionable insights to elevate your digital marketing efforts.
The 7th edition of PPC Trends explores the challenges and opportunities presented by the onslaught of AI tools, and provides actionable tips for thriving.
Discover the latest trends, tips, and strategies in SEO and PPC marketing. Our curated articles offer in-depth analysis, practical advice, and actionable insights to elevate your digital marketing efforts.
Join three of Reddit’s top executives in this exclusive AMA (Ask Me Anything) to discover how you can tap into Reddit’s unique platform to drive brand growth.
Join this leadership discussion for proven techniques to build long-term relationships and keep your clients coming back.
Compression can be used by search engines to detect low-quality pages. Although not widely known, it’s useful foundational knowledge for SEO
The concept of Compressibility as a quality signal is not widely known, but SEOs should be aware of it. Search engines can use web page compressibility to identify duplicate pages, doorway pages with similar content, and pages with repetitive keywords, making it useful knowledge for SEO.
Although the following research paper demonstrates a successful use of on-page features for detecting spam, the deliberate lack of transparency by search engines makes it difficult to say with certainty if search engines are applying this or similar techniques.
In computing, compressibility refers to how much a file (data) can be reduced in size while retaining essential information, typically to maximize storage space or to allow more data to be transmitted over the Internet.
Compression replaces repeated words and phrases with shorter references, reducing the file size by significant margins. Search engines typically compress indexed web pages to maximize storage space, reduce bandwidth, and improve retrieval speed, among other reasons.
A bonus effect of using compression is that it can also be used to identify duplicate pages, doorway pages with similar content, and pages with repetitive keywords.
This research paper is significant because it was authored by distinguished computer scientists known for breakthroughs in AI, distributed computing, information retrieval, and other fields.
One of the co-authors of the research paper is Marc Najork, a prominent research scientist who currently holds the title of Distinguished Research Scientist at Google DeepMind. He’s a co-author of the papers for TW-BERT, has contributed research for increasing the accuracy of using implicit user feedback like clicks, and worked on creating improved AI-based information retrieval (DSI++: Updating Transformer Memory with New Documents), among many other major breakthroughs in information retrieval.
Another of the co-authors is Dennis Fetterly, currently a software engineer at Google. He is listed as a co-inventor in a patent for a ranking algorithm that uses links, and is known for his research in distributed computing and information retrieval.
Those are just two of the distinguished researchers listed as co-authors of the 2006 Microsoft research paper about identifying spam through on-page content features. Among the several on-page content features the research paper analyzes is compressibility, which they discovered can be used as a classifier for indicating that a web page is spammy.
Although the research paper was authored in 2006, its findings remain relevant to today.
Then, as now, people attempted to rank hundreds or thousands of location-based web pages that were essentially duplicate content aside from city, region, or state names. Then, as now, SEOs often created web pages for search engines by excessively repeating keywords within titles, meta descriptions, headings, internal anchor text, and within the content to improve rankings.
Section 4.6 of the research paper explains:
“Some search engines give higher weight to pages containing the query keywords several times. For example, for a given query term, a page that contains it ten times may be higher ranked than a page that contains it only once. To take advantage of such engines, some spam pages replicate their content several times in an attempt to rank higher.”
The research paper explains that search engines compress web pages and use the compressed version to reference the original web page. They note that excessive amounts of redundant words results in a higher level of compressibility. So they set about testing if there’s a correlation between a high level of compressibility and spam.
They write:
“Our approach in this section to locating redundant content within a page is to compress the page; to save space and disk time, search engines often compress web pages after indexing them, but before adding them to a page cache.
…We measure the redundancy of web pages by the compression ratio, the size of the uncompressed page divided by the size of the compressed page. We used GZIP …to compress pages, a fast and effective compression algorithm.”
The results of the research showed that web pages with at least a compression ratio of 4.0 tended to be low quality web pages, spam. However, the highest rates of compressibility became less consistent because there were fewer data points, making it harder to interpret.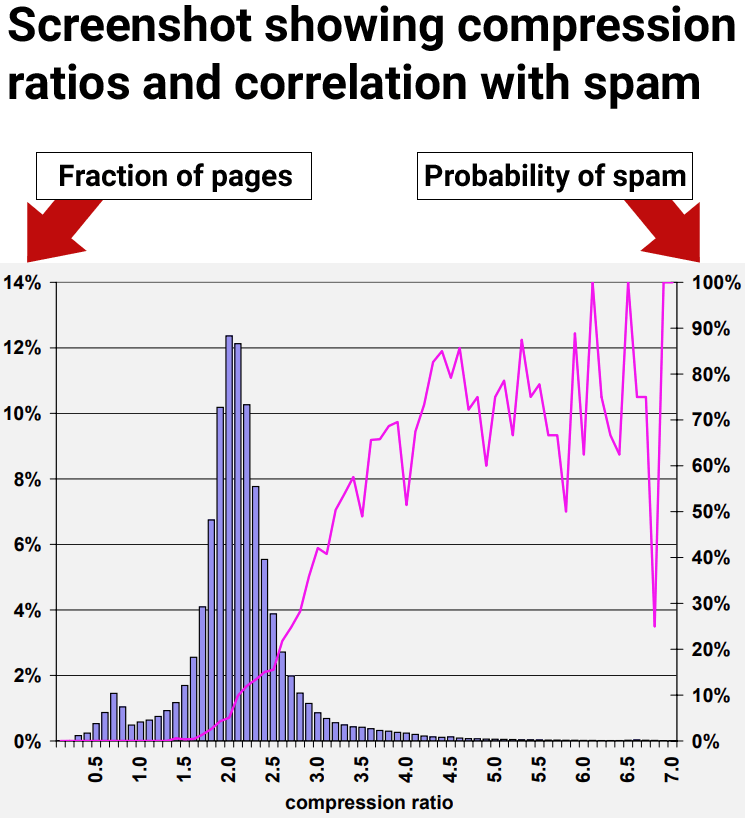
The researchers concluded:
“70% of all sampled pages with a compression ratio of at least 4.0 were judged to be spam.”
But they also discovered that using the compression ratio by itself still resulted in false positives, where non-spam pages were incorrectly identified as spam:
“The compression ratio heuristic described in Section 4.6 fared best, correctly identifying 660 (27.9%) of the spam pages in our collection, while misidentifying 2, 068 (12.0%) of all judged pages.
Using all of the aforementioned features, the classification accuracy after the ten-fold cross validation process is encouraging:
95.4% of our judged pages were classified correctly, while 4.6% were classified incorrectly.
More specifically, for the spam class 1, 940 out of the 2, 364 pages, were classified correctly. For the non-spam class, 14, 440 out of the 14,804 pages were classified correctly. Consequently, 788 pages were classified incorrectly.”
The next section describes an interesting discovery about how to increase the accuracy of using on-page signals for identifying spam.
The research paper examined multiple on-page signals, including compressibility. They discovered that each individual signal (classifier) was able to find some spam but that relying on any one signal on its own resulted in flagging non-spam pages for spam, which are commonly referred to as false positive.
The researchers made an important discovery that everyone interested in SEO should know, which is that using multiple classifiers increased the accuracy of detecting spam and decreased the likelihood of false positives. Just as important, the compressibility signal only identifies one kind of spam but not the full range of spam.
The takeaway is that compressibility is a good way to identify one kind of spam but there are other kinds of spam that aren’t caught with this one signal. Other kinds of spam were not caught with the compressibility signal.
This is the part that every SEO and publisher should be aware of:
“In the previous section, we presented a number of heuristics for assaying spam web pages. That is, we measured several characteristics of web pages, and found ranges of those characteristics which correlated with a page being spam. Nevertheless, when used individually, no technique uncovers most of the spam in our data set without flagging many non-spam pages as spam.
For example, considering the compression ratio heuristic described in Section 4.6, one of our most promising methods, the average probability of spam for ratios of 4.2 and higher is 72%. But only about 1.5% of all pages fall in this range. This number is far below the 13.8% of spam pages that we identified in our data set.”
So, even though compressibility was one of the better signals for identifying spam, it still was unable to uncover the full range of spam within the dataset the researchers used to test the signals.
The above results indicated that individual signals of low quality are less accurate. So they tested using multiple signals. What they discovered was that combining multiple on-page signals for detecting spam resulted in a better accuracy rate with less pages misclassified as spam.
The researchers explained that they tested the use of multiple signals:
“One way of combining our heuristic methods is to view the spam detection problem as a classification problem. In this case, we want to create a classification model (or classifier) which, given a web page, will use the page’s features jointly in order to (correctly, we hope) classify it in one of two classes: spam and non-spam.”
These are their conclusions about using multiple signals:
“We have studied various aspects of content-based spam on the web using a real-world data set from the MSNSearch crawler. We have presented a number of heuristic methods for detecting content based spam. Some of our spam detection methods are more effective than others, however when used in isolation our methods may not identify all of the spam pages. For this reason, we combined our spam-detection methods to create a highly accurate C4.5 classifier. Our classifier can correctly identify 86.2% of all spam pages, while flagging very few legitimate pages as spam.”
Misidentifying “very few legitimate pages as spam” was a significant breakthrough. The important insight that everyone involved with SEO should take away from this is that one signal by itself can result in false positives. Using multiple signals increases the accuracy.
What this means is that SEO tests of isolated ranking or quality signals will not yield reliable results that can be trusted for making strategy or business decisions.
We don’t know for certain if compressibility is used at the search engines but it’s an easy to use signal that combined with others could be used to catch simple kinds of spam like thousands of city name doorway pages with similar content. Yet even if the search engines don’t use this signal, it does show how easy it is to catch that kind of search engine manipulation and that it’s something search engines are well able to handle today.
Here are the key points of this article to keep in mind:
Detecting spam web pages through content analysis
Featured Image by Shutterstock/pathdoc
I have 25 years hands-on experience in SEO, evolving along with the search engines by keeping up with the latest …
Conquer your day with daily search marketing news.
Join Our Newsletter.
Get your daily dose of search know-how.
In a world ruled by algorithms, SEJ brings timely, relevant information for SEOs, marketers, and entrepreneurs to optimize and grow their businesses — and careers.
Copyright © 2024 Search Engine Journal. All rights reserved. Published by Alpha Brand Media.
Google Zero is here — now what? – The Verge
By Nilay Patel, editor-in-chief of the Verge, host of the Decoder podcast, and co-host of The Vergecast.
We’ve been covering big changes to Google and Google Search very closely here on Decoder and The Verge. There’s a good reason for that: the entire business of the modern web is built around Google.
It’s a whole ecosystem. Websites get traffic from Google Search, they all get built to work in Google Chrome, and Google dominates the stack of advertising technologies that turn all of it into money. It’s honestly been challenging to explain just how Google operates as a platform, because it’s so large, pervasive, and dominant that it’s almost invisible.
But if you think about it another way — considering the relationship YouTubers have to YouTube or TikTokers have to the TikTok algorithm — it starts to become clear. The entire web is Google’s platform, and creators on the web are often building their entire businesses on that platform, just like any other.
I think about Decoder as a show for people who are trying to build things, and the number one question I have for people who build things on any platform is: what are you going to do when that platform changes the rules?
There’s a theory I’ve had for a long time that I’ve been calling “Google Zero” — my name for that moment when Google Search simply stops sending traffic outside of its search engine to third-party websites.
Regular Decoder listeners have heard me talk a lot about Google Zero in the last year or two. I asked Google CEO Sundar Pichai about it directly earlier this month. I’ve also asked big media executives, like The New York Times’ Meredith Kopit Levien and Fandom’s Perkins Miller, how it would affect them. Nobody has given me a good answer — and it seems like the media industry still thinks it can deal with it when the time comes. But for a lot of small businesses. Google Zero is now. It’s here, it’s happening, and it can feel insurmountable.
Earlier this year, a small site called HouseFresh, which is dedicated to reviewing air purifiers, published a blog post that really crystallized what was happening with Google and these smaller sites. HouseFresh managing editor Gisele Navarro titled the post “How Google is killing independent sites like ours,” and she had receipts. The post shared a whole lot of clear data showing what specifically had happened to HouseFresh’s search traffic — and how big players ruthlessly gaming SEO were benefiting at their expense.
I wanted to talk to Gisele about all of this, especially after she published an early May follow-up post with even more details about the shady world of SEO spam and how Google’s attempts to fight it have crushed her business.
I often joke that The Verge is the last website on Earth, but there’s a kernel of truth to it. Building an audience on the web is harder than ever, and that leaves us with one really big question: what’s next?
Folks like Gisele, who make all the content Google’s still hoovering up but not really serving to users anymore, have a plan.
/ Sign up for Verge Deals to get deals on products we’ve tested sent to your inbox weekly.
The Verge is a vox media network
© 2024 Vox Media, LLC. All Rights Reserved
Han So Hee and Jeon Jong Seo maintain close bond despite recent rumors – allkpop
39
30
Recently, Han So Hee shared several photos on her personal SNS account.
Without any special captions, the photos featured Han So Hee in her daily life, as well as some that appeared to be taken on set.
What caught people’s attention was the comment left on the post. Fellow actor Jeon Jong Seo, known to be a close friend, commented, “Beautiful~~”. Han So Hee replied with, “Thank you, potato,” highlighting their enduring friendship.
Previously, Han So Hee was embroiled in a controversy involving accusations of using a secondary account to leave malicious comments on actor Hyeri’s SNS. The suspicion grew when it was noted that Jeon Jong Seo, a close friend, followed the alleged account.
Regarding the matter, Jeon Jong Seo’s agency, Andmarq, stated cautiously, “It is difficult to verify as it involves private matters.”
Meanwhile, Han So Hee’s agency, 9ato Entertainment, clarified, “We would like to address the reports regarding actor Han So Hee. The SNS account mentioned in the media does not belong to Han So Hee.”
Han So Hee’s side also emphasized through an official SNS statement, “The SNS account mentioned in the media does not belong to Han So Hee, and we will take full legal responsibility if this proves to be false. We also ask that people refrain from spreading unverified speculation.”

Jung Kyung Ho travels to Japan to support Sooyoung’s single showcase
NCT’s Doyoung announces new single release for November 6th
SEND
Inside the Google algorithm – The Verge
By David Pierce, editor-at-large and Vergecast co-host with over a decade of experience covering consumer tech. Previously, at Protocol, The Wall Street Journal, and Wired.
The algorithm that powers Google Search is one of the most important, most complicated, and least understood systems that rule the internet. As of this week, though, we understand it a little better. Thanks to a huge leak of API documentation, we got an unprecedented look at what Google cares about, how it ranks content, and how it thinks the internet should work. The leaked documentation is dense, and it doesn’t tell us everything about how Google ranks, but it does offer a set of signals we’ve never seen before.
On this episode of The Vergecast, we discuss everything in the leaked documents, the SEO community’s reaction, the potential regulatory implications of it all, and what it means to build a website in 2024.
After that, we talk about the recent spate of media companies (including Vox Media, The Verge’s parent company) making content and technology deals with OpenAI. Are media companies making the same mistakes they did with Facebook and others, or are they actually trying to make sure they don’t make those mistakes again? We have a lot of thoughts, and we also want to hear from you in particular — disclosure is The Verge’s brand, after all, and we want to know how you think we should talk about all this. Email us at vergecast@theverge.com, call the hotline at 866-VERGE11, and tell us everything on your mind.
Finally, we do a lightning round of other tech news, including Apple’s AI plans at WWDC, Discord’s kinda-sorta pivot, a Fitbit for kids, “edgy” engagement, and the Sony party speaker The Verge’s Nilay Patel can’t stop talking about.
If you want to know more about everything we discuss in this episode, here are some links to get you started, beginning with the Google leak:
And on OpenAI:
And in the lightning round:
/ Sign up for Verge Deals to get deals on products we’ve tested sent to your inbox weekly.
The Verge is a vox media network
© 2024 Vox Media, LLC. All Rights Reserved